June 20, 2025
Instant Answers, On-Demand

How Augment 1x reads your context and serves the perfect reply the moment you ask.
Posted by Amanda
8 minutes read
Introduction
The cursor blinks, a silent judge in the live coding interview. Your mind races, trying to recall that obscure pandas function for merging dataframes. Your fingers hover over the keyboard, and just as the thought solidifies, you tap your designated hotkey. Instantly, Augment 1x surfaces the exact API call you needed: pd.merge(…). It's not magic, it's a meticulously crafted fusion of multimodal data and on-demand intelligence. In our last post (if you haven't read it yet, go check out the architectural deep-dive!), we pulled back the curtain on Augment 1x's underlying structure. Now, let's explore the learning tricks that make this assistant feel less like a tool and more like an extension of your own thoughts, always ready at your command.
Multimodal Insight: Understanding Your World
Augment 1x's ability to provide the right answer precisely when you need it stems from its constant, low-impact analysis of your multimodal environment. It's not just passively watching; it's intelligently processing.
Rolling Window Intent Detection
Imagine a causal transformer continuously analyzing not just your code, but your cursor position, your keystrokes, your open applications, and even relevant content on your screen. This rolling window intent detection allows Augment 1x to build a real-time, nuanced understanding of your immediate context and potential goals. It's like having a hyper-aware, context-sensitive companion, quietly gathering clues about your intentions.
Speculative Generation (Under the Hood)
While Augment 1x doesn't display answers until you press the hotkey, it's still leveraging speculative generation behind the scenes. Based on the rich multimodal data it's constantly collecting, it's silently drafting potential responses and suggestions, so when you do hit that hotkey the relevant answer is already primed and ready, resulting in near-instantaneous feedback.
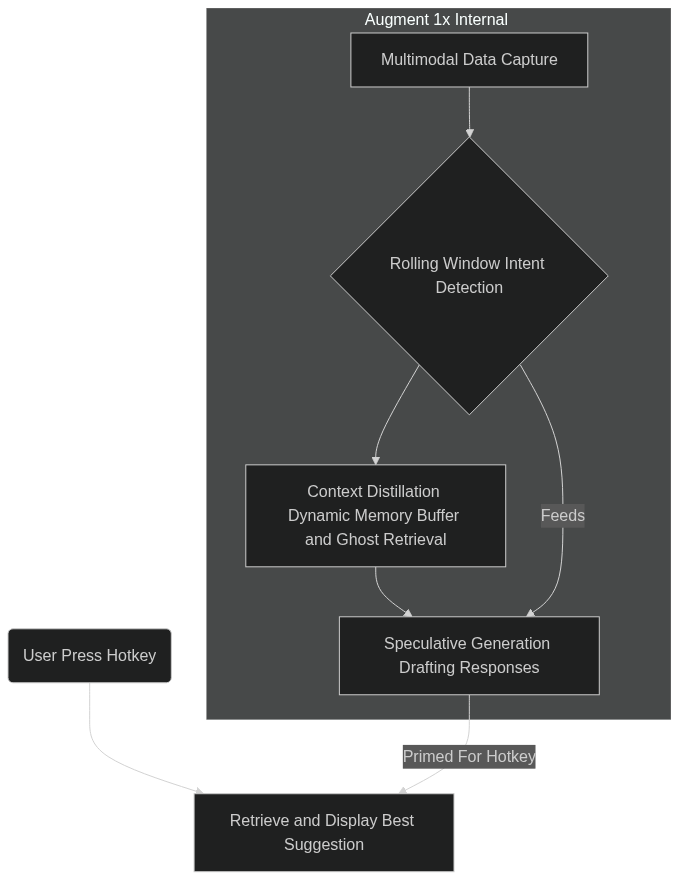
Figure 1. Predict-Then-Plan Loop
Context Distillation: Smart, Not Sprawling Memory
To maintain its lightning-fast responsiveness and ensure it's always giving you the most relevant information, Augment 1x doesn't try to remember everything. Instead, it employs clever context distillation techniques.

Figure 2. Context Distillation Process
Dynamic Memory Buffer
At its core is a dynamic memory buffer, essentially a key-value store limited to your last 'N' interactions and the most pertinent aspects of your current multimodal context. This ensures that the most relevant and recent information is always immediately accessible, without the overhead of sifting through vast amounts of historical data.
"Ghost" Retrieval
Every 250 milliseconds, Augment 1x performs a "ghost" retrieval – a Qdrant vector probe that silently searches for related information in the background. This proactive approach allows it to pre-fetch potentially useful knowledge based on your evolving context, ensuring that when you activate it with the hotkey, the necessary information is already at its fingertips.
Opportunistic Fine-Tuning: Learning Just Like You Do
Augment 1x doesn't just learn from its developers; it learns from you.
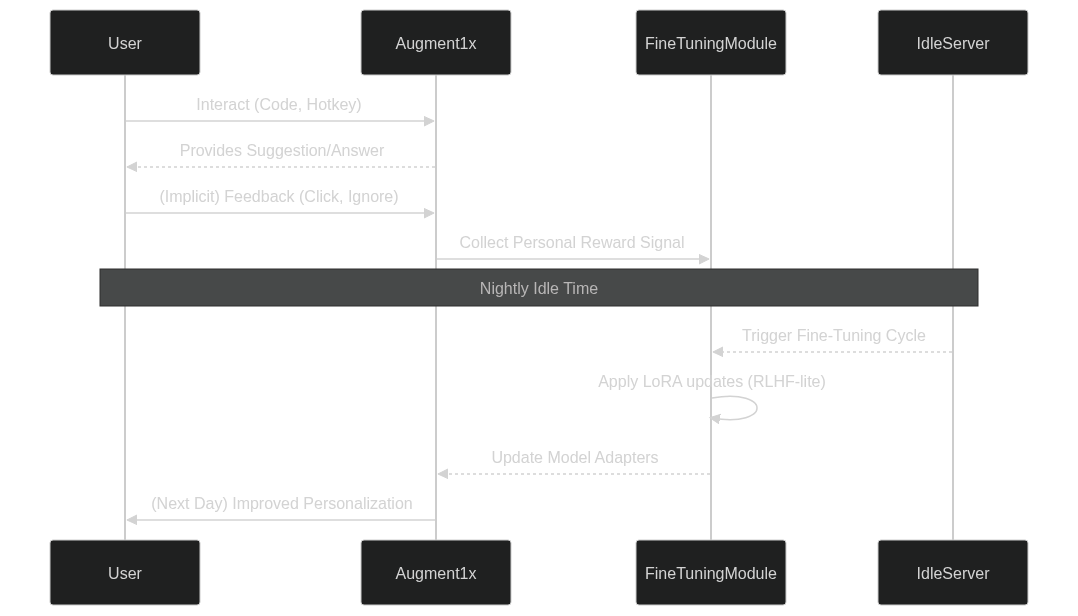
Figure 3. Opportunistic Fine-Tuning
Low-Rank Adapters (LoRA)
During your nightly idle-time, when your machine is resting, Augment 1x is busy slotting in low-rank adapters (LoRA). These lightweight modules allow for highly efficient model updates, subtly fine-tuning the assistant to your specific coding style, preferences, and common pitfalls without requiring a complete retraining of the entire model.
Personal Reward Signals
Every interaction is a learning opportunity. Did you click on a suggestion after hitting the hotkey? That's a positive reward signal. Did you ignore a suggestion, or rephrase your code in a different way? Those are also signals, feeding into an RLHF-lite process. Over time, Augment 1x learns what works best for you, making its assistance increasingly personalized and effective.
Cost & Energy Tricks: Efficiency You Can't Detect
All this intelligence wouldn't be practical if it drained your battery or hogged your CPU. Augment 1x is engineered for stealthy efficiency.
Quantization-Aware Training
Through quantization-aware training, Augment 1x can operate effectively with models compressed down to 4-bit precision without any catastrophic forgetting. This dramatically reduces memory footprint and computational requirements, making it feasible to run locally.
Selective Layer Execution
Not every part of the model needs to be active all the time. Augment 1x employs selective layer execution, skipping certain layers if the input entropy falls below a certain threshold (τ). This means less computation for simpler tasks, conserving valuable resources.
Measuring 'Undetectability': Blending into Your Workflow
The true test of Augment 1x's efficiency is its "undetectability." We don't want it to feel like another process running in the background, but rather an integrated part of your system. We meticulously monitor CPU/GPU/thermal fingerprints against baseline idle curves to ensure Augment 1x is a quiet partner. Our benchmarks show an average power delta of less than 3 Watts during peak assistance, meaning it sips power rather than guzzles it. It's designed to be there precisely when you hit that hotkey, and practically invisible when you don't.
Closing Thoughts
Augment 1x is more than just an AI assistant; it's a testament to how intelligent machine learning can seamlessly integrate into your daily workflow, anticipating your needs and empowering you to code faster and smarter – all at the tap of a button. What are your thoughts on on-demand, context-aware AI? How do you think such capabilities could further enhance your development process? Share your feedback in the comments below! Stay tuned for our next post, where we'll delve into the crucial ethical safeguards we've built into Augment 1x to ensure responsible and secure AI assistance.